
대화형 인공지능 기반 다국어 자동통역 서비스 현황과 핵심 기술
●
●
●
* 본 내용은 김상훈 책임연구원(☎ 042-860-5141, ksh@etri.re.kr)에게 문의하시기 바랍니다.
** 본 내용은 필자의 주관적인 의견이며 IITP의 공식적인 입장이 아님을 밝힙니다.
1970년대부터 언어장벽 해소를 위해 국내외에서 자동통역 연구가 지속적으로 이루어졌으나 음성언어 데이터의 비정형 특성과 번역 언어 간 어순의 불일치 등으로 확률/통계 수학적 모델링으로는 한계가 있었다. 최근 대용량 데이터를 활용한 딥러닝을 통해 한계 극복 가능성이 보임에 따라 해외여행자 대상 간단한 일상회화 수준 언어소통에서 비즈니스 회의와 같이 전문용어가 포함된 난이도 높은 회의 통역까지 서비스가 적용되고 있다. 따라서 본 고에서는 대화형 인공지능 기반 자동통역 기술의 국내외 최신 동향을 살펴보고, 특히 서울지하철 11개 지역 주요 역사에 실시하고 있는 다국어 자동통역 서비스 핵심기술에 대해 알아보고자 한다. 서울지하철은 미국 뉴욕, 일본 동경과 함께 세계 3대 메트로 시스템으로 명동, 광화문, 강남 등 외국인이 가장 많이 이용하는 지하철 역사에 국내 자체 개발한 자동통역 기술이 활용되는 사례는 외국인에게 한국 관광의 편의성 제공뿐만 아니라 국내 인공지능 기술의 우수성을 알리는 등 큰 의미가 있다. 향후 공공기관, 호텔, 백화점 등에 확산되어 일상생활 속으로 널리 사용되는 계기가 될 것으로 보인다.
II. 국내외 현황
최근 갤럭시 S24 스마트폰 모델에 탑재된 온디바이스 통역은 상대방과 전화를 통해 원격으로 실시간 자동통역 기능을 제공하며, 네트워크가 안되는 상황에서도 외국인과의 의사소통을 가능하게 해준다[1]. 여행하는 동안 발생하는 긴급상황, 식당 이용, 호텔 예약, 관광 정보 안내, 비즈니스 대화 등 다양한 상황에서 실시간으로 통역할 수 있다. 사용 방법은 사용자의 음성을 실시간으로 인식 및 번역하여 상대방 화면에 출력되거나 상대방의 언어 번역 결과를 사용자의 화면에 출력한다. 현재 자동통역이 가능한 언어로는 중국어, 영어, 불어, 독어, 힌디어, 이탈리아어, 일어, 한국어, 폴란드어, 남미 포르투갈어, 유럽, 남미 스페인어, 태국어, 베트남어 등 출시 기준 13개 언어가 제공되며, 향후 언어가 추가될 예정이다.
<자료> 비즈니스 포스트, “저커버그의 메타버스에는 언어장벽 없다, 실시간 통역기술 선보여”, 2022. 2.
마이크로소프트, “마이크로소프트, 현실이 된 메타버스ㆍAIㆍ초연결 기술 대거 공개”, 2021. 11.
지디넷코리아, “구글, AR글래스 시제품 공개…외국어 실시간 번역”, 2022. 5.
[그림 1] 메타, 마이크로소프트 및 구글의 자동통역 서비스 방향
한편, LLM(Large Language Model) 기반 ChatGPT를 개발한 미국의 Open AI사는 60개 언어를 인식할 수 있는 음성인식용 Whisper 모델을 공개하였고, ChatGPT 기반으로도 다국어 번역 기능을 제공하여 국내 사용자들에게 좋은 인상을 주고 있다. 또한, [그림 1]과 같이 SNS 시장에서 절대강자인 메타(구, 페이스북)는 53개 다국어 사전학습(Pretraining model) 모델을 공개하고 있으며, 100여개 언어에 대한 다국어 통역 서비스를 제공 중에 있다[그림 1]. 이와 같이 글로벌 기업들이 앞다투어 60~100여개 언어가 가능한 통역 기능을 전세계적으로 공개하고 있으나 공개 모델에 사용된 학습 데이터 중 영어가 70% 비중을 차지하고 있어 주로 영어 음성인식이나 영어 기반 통역에 주력하고 있다. 중국은 TCL, 샤오미 등 기업들이 음성인식 기술을 탑재한 다양한 인공지능 제품을 출시하고 있고, 중국 내 방언을 인식하거나 통역하는 것에 기술적으로 차별화하고 있다[2].
최근 일본의 VoicePing은 회의 통역 상황에서 최대 45개 언어가 가능한 실시간 자막을 제공한다. 특히, VoicePing은 아시아 언어의 특성을 고려한 음성인식 및 번역 모델을 개발하여 기술적 차별화를 꾀하고 있다. 이와 같이 앞으로는 음성인식이나 자동통역의 핵심 기술을 이용한 대화형 챗봇, 디지털 휴먼, 개인비서 등 대화형 서비스가 큰 시장을 형성할 것으로 예상한 바, 글로벌 기업들은 교감/공감이 가능한 Conversational AI 기술 확보 경쟁이 치열하다. 2021년 코로나가 유행하던 시기에 잠깐 유행했던 가상 환경인 메타버스는 기술적 완성도를 높여야 하는 숙제를 안고 있고, 이에 대한 연구가 ETRI를 중심으로 활발하게 연구되고 있다. 향후 메타버스 등 패러다임 전환으로 새로운 비즈니스 시장이 열리는 경우, 국가 간 물리적 장벽이 사라짐에 따라 가상공간에서 언어 장벽 해소가 시급히 해결해야 할 문제로 보인다. 2022년 초 메타는 메타버스 환경에서 글로벌 언어소통을 위한 ‘BabelFish’ 전략을 수립하여 세계 100여개 언어 간 자동통역 기술을 확보한다고 천명한 바 있다. 이와 같이 인공지능의 도입으로 음성인식 및 자동통역 성능이 대폭 개선되어 실생활에 적용할만한 수준으로 향상됨에 따라 이를 기반으로하는 AI 비서, AI 통역사 AI 콜센터, 대화 로봇 등 기술이 일상생활 속으로 확산 중이다.
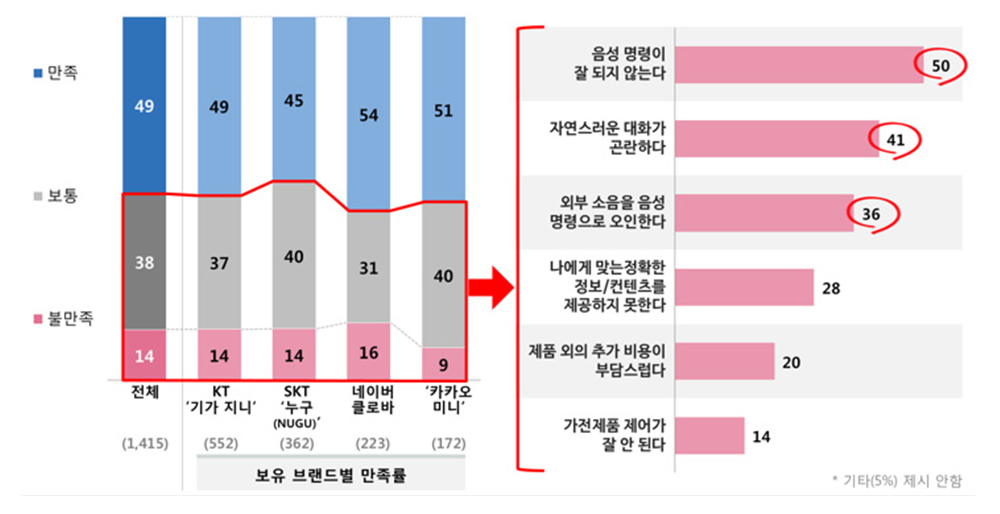
<자료> 콘슈머인사이트, “뜨거운 AI 스피커 시장, 차가운 소비자 평가”, 2018.
[그림 2] AI 스피커 사용자 만족도 조사(2020년 하반기, 컨슈머리포트)
그러나 음성을 기반으로 하는 AI 서비스를 사용하는 현장에서는 원거리 발성, 소음 환경, 사투리, 신조어, 구어체, 즉흥발화 등으로 인해 사용자가 음성으로 편하게 이용하기에는 여전히 기대에 못 미친다는 불만이 많다. [그림 2]와 같이, 2018년 하반기에 이동통신 리서치 업체인 컨슈머리포트가 35,676명을 대상으로 AI 스피커 사용자 만족도 조사에서 가정 내 소음환경 인식 오류, 사람과 같이 자연스러운 대화 불가, 명령어 오인식 등 음성인식률이 낮음 순으로 불만족이 높았으며, 최근까지도 이런 문제가 해결되지 못하고 있다[그림 2]. 사용자 편의성 측면에서도 그 동안 자연스러운 대화로 양방향 통역이 이루어질 수 있는 인터페이스가 제공되지 못해 주로 개인이 보유하고 있는 스마트폰 화면의 터치스크린을 통해 마이크 활성 버튼을 누르고 음성을 입력한 다음, 자동으로 번역된 결과를 화면으로 상대방에게 보여주거나 음성합성으로 들려주는 방식이 일반적이었다.

<자료> 한국전자통신연구원 자체 작성
[그림 3] 자동통역 핵심기술 구성도 및 투명디스플레이를 이용한 대화형 양방향 통역 시연
최근 [그림 3]과 같이 LCD 또는 OLED 기반의 투명 디스플레이가 소형화 고품질화 제품이 출시되면서 얼굴을 서로 마주 보면서 통역이 이루어질 수 있는 인터페이스 제공이 가능하게 되어 외국인과 언어소통 시 자연스러운 자동통역 인터페이스로 부상하고 있다[그림 3]. 물론, 휴대형은 아니지만 호텔이나 백화점, 지하철 등 외국인 여행객들이 자주 찾는 지점에서는 고정적으로 대화로 언어소통이 가능해서 자동통역 서비스가 대중화하는 데 기여할 것이다.
서울시 산하 공공기관인 서울교통공사는 2023년 12월부터 3개월간 외국인이 가장 많이 찾는 명동역에서 13개 언어 자동통역 시스템을 시범 운영하였다. 이를 통해 외국인 관광객이 어떻게 이용하는지 현황과 서비스 만족도 등을 모니터링하고 개선 사항을 발굴, 보완했다[3]. 특히, 지하철 역명과 철도 용어 등 고유명사나 전문용어에 대한 인공지능 학습을 통해 지하철에서 발생하는 긴급상황에서 외국인과 역무원 간 모국어를 사용하여 원활한 의사소통이 이루어지도록 보완했다. 역사 내 개찰구 기기 작동 소리, 스피커 안내음성, 주변 대화 등 다양한 고소음 환경에서 인식ㆍ번역 장애 해결을 위해 잡음에 강인한 인공지능 모델링 기술을 적용하는 등 시스템을 고도화했다.
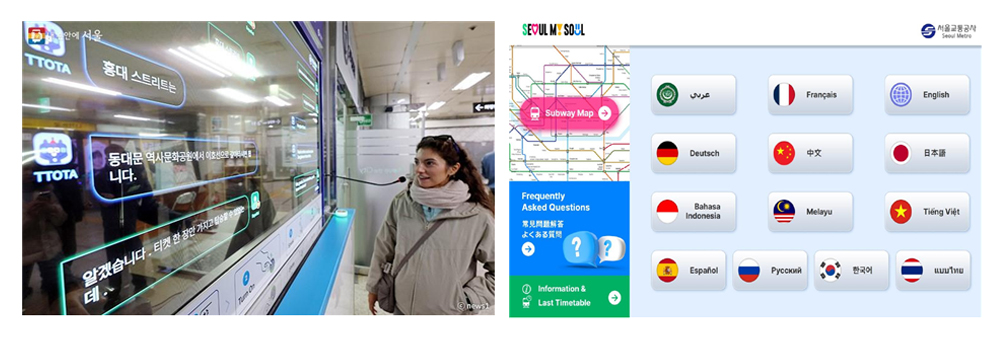
<자료> 서울특별시, “자동 통역되는 투명 스크린, 서울지하철 11개 역으로 확대된다”, 2024. 3.
[그림 4] 서울지하철 역에 설치된 13개 언어 다국어 자동통역 서비스
이와 같이 명동역 대상 자동통역 시범운영을 통해 도출된 문제점을 보완하고 동시 접속 서비스 시스템 안정화를 거쳐 서울교통공사는 외국인 관광객의 지하철 이용 시 불편 해소를 위해 [그림 4]와 같이 ‘외국어 동시 대화 시스템’을 주요 지역으로 확대 운영하기로 했다[그림 4]. 이번 확대 운영으로 종로5가역, 시청, 홍대입구, 을지로입구, 강남역, 경복궁역, 명동역, 광화문, 김포공항역, 이태원, 공덕역 등 11곳에서 자동통역 시스템을 이용할 수 있다[4]. 이 시스템은 외국인과 역 직원이 투명 디스플레이를 마주 보고 대화하면 원격으로 운영되는 자동통역 시스템을 거쳐 디스플레이에 나라별 텍스트로 표출되는 방식이다. 현재 동시 대화가 가능한 언어는 한국어, 영어, 일본어, 중국어, 프랑스어, 스페인어, 독일어, 러시아어, 태국어, 베트남어, 말레이시아어, 인도네시아어, 아랍어 등 13개 언어가 된다. 서울 지하철역 자동통역 서비스를 시작으로 다양한 외국어 서비스에 대한 생활 밀착형 수요가 급증함에 따라 국내 인공지능 전문업체는 서울교통공사 자동통역 서비스를 응용하여 최신 인공지능 음성 기술을 탑재한 동시통역 솔루션을 출시하여 외국인 이용 수요에 적극적으로 대응하고 있다. 최근 파라다이스 호텔 카지노, 롯데백화점 잠실점에도 설치를 마쳐 이를 계기로 타 백화점이나 호텔 등 자동통역 서비스가 확산될 것으로 예상된다.
III. 다국어 대화형 자동통역 핵심 기술
자동통역 기술은 크게 음성인식(Speech recognition), 기계번역(Machine translation) 음성합성(Speech synthesis) 등 핵심 기술로 구성되고, 각 기술은 현재 종단형 트랜스포머 모델로 각종 평가셋에 대해 SOTA(State-Of-The-Art)로 평가되고 있다[5]. 3가지 핵심 기술에 대해서는 이미 잘 알려져 있어, 본 고에서는 다국어 자동통역 구현 시 발생하는 실질적인 문제인 다국어 확장의 어려움, 비용 절감을 위한 모델 통합 방안, 구어체 번역 및 언어 간 상이한 특성으로 인한 최적 번역 모델링 방법, 음성인식 결과로부터 구두점 복원 및 외국인의 한국어 고유명사 발성 문제 등 해결 방안을 다루고자 한다.
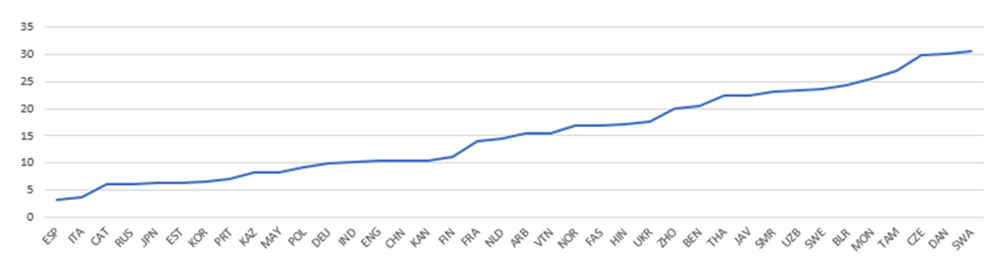
1. 다국어 확장 기술 다국어 자동통역 기술 개발에 가장 어려운 부분은 인공지능 학습용 다국어 음성언어 및 번역 데이터 확보에 있다. [그림 5]와 같이 세계적으로 주요 언어인 한, 중, 영, 일은 동남아 언어나 유럽어, 아랍어, 인도어, 남미 등에 비해 확보가 다소 용이하나 동남아어 등 희소한 언어의 경우 대용량 학습 데이터 확보가 매우 어렵다[그림 5]. 더구나 최근에는 언어별 수만 시간 이상 음성과 수백만 규모의 대역 문장이 필요한 바, 다국어로 확장하기에는 비용 측면이나 확보에 필요한 시간 등 국내 연구개발 실정상 매우 어렵다. [그림 6]은 구글에서 공개한 평가셋(feurs)으로 각 언어별 음성인식 성능을 평가한 결과로, 데이터 크기에 성능이 비례함을 알 수 있다[그림 6]. 이에 데이터 확보가 어려운 low resource 언어에 대해서는 데이터 확보 측면뿐만 아니라 기술적인 접근 방식이 더 절실히 필요하다. 이러한 문제는 국내에만 국한된 것이 아니기 때문에 해외에서도 희소한 언어에 대한 데이터 문제를 해결하기 위해 활발한 연구가 진행되고 있다.
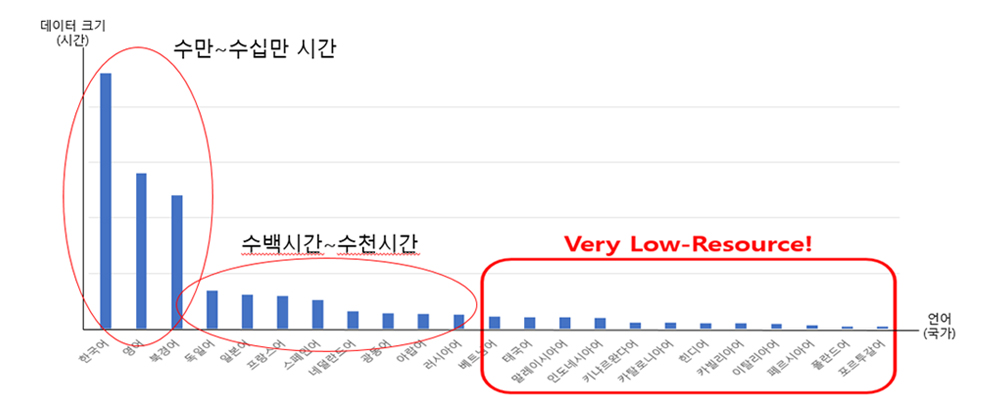
<자료> 한국전자통신연구원 자체 작성
[그림 5] 다국어 확장 시 데이터 확보가 어려운 희소한 언어
<자료> 한국전자통신연구원 자체 작성
[그림 6] 구글 평가셋(feurs)에 대한 언어별 음성인식 성능(CER: Character Error Rate, %)
한국전자통신연구원(ETRI)에서 유사언어를 단일 모델로 통합하거나 전사 레이블이 없는 음성 데이터를 활용하는 방법, 음성합성기를 이용한 인공적인 음성 데이터 생성을 통한 증강 등 언어 확장을 시도하고 있고, 일부 시도 기술은 성능 개선에 기여가 있는 것으로 평가되고 있다. 이와 같이, 다양한 기술적 접근 방식을 통해 2022년 ETRI는 주요 외국어 24개 언어를 인식할 수 있는 『대화형 인공지능(Conversational AI) 기술』을 개발했다. ETRI가 개발한 다국어 확장이 가능한 음성인식 성능은 구글, 메타 등 글로벌 업체와 비교해 중국어, 영어 등 주요 언어에 대해서는 동등 수준을 확보하였고, 희소 언어에 대해서는 서비스에 특화된 파인튜닝 모델링을 통해 성능을 높였다.
<자료> 한국전자통신연구원 자체 작성
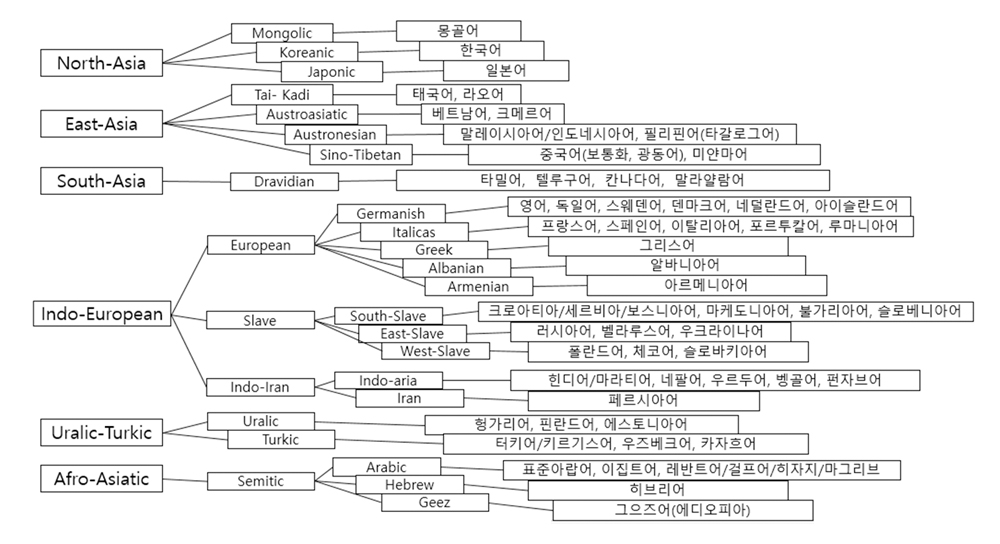
[그림 7] 언어 간 문법적, 파생적 유사성에 따른 분류
종단형 음성 인식 기술의 배치(batch) 처리로 인한 응답속도가 느린 문제는 종단형 스트리밍(streaming) 추론 기술을 개발, 실시간 처리가 되도록 개선했다. 아울러, 공공, 학술, 과학기술, 무역, 의료, 법률 등 특정 도메인에 대한 음성인식 특화가 쉽도록 하이브리드 종단형 인식 기술도 개발해 적용했다. 추후 언어를 확장하기 위해 언어 간 문법적 유사성이나 파생 관련성을 근거로 [그림 7]과 같이 언어를 분류하여 희소한 언어와 유사한 특성을 가진 데이터를 모아 양적으로 늘려서 학습이 가능하도록 데이터를 설계, 구축하였다[그림 7].
2. 다국어 음성인식 통합 모델링 기술 서울지하철에 적용한 다국어 자동통역 서비스는 13개 언어별 음성인식 엔진과 24개 자동번역 엔진 등 총 36개의 엔진이 하나의 서버에 가동 중이며, 서울지하철 11개 역을 동시에 끊김 없는 서비스를 제공하기 위해 엔진 당 평균 2~3개 동시 접속이 가능하도록 운영되고 있다. 이와 같이, 13개 언어에 대한 다국어 자동통역 서비스를 실시간으로 제공을 위해 서버 부담이 매우 가중되고 있는 상황에서 백화점이나 호텔 등 서비스가 확대된다면 서버 운용비용이 증가하기 때문에 시스템을 효율적으로 운용하는 방안이 필요하다.
<자료> 한국전자통신연구원 자체 작성
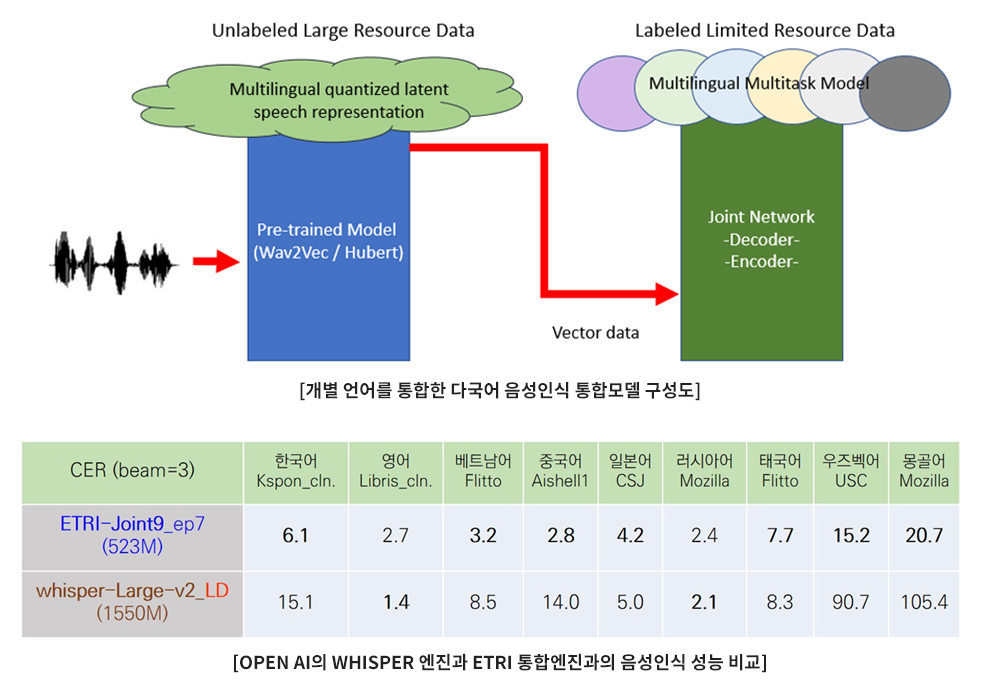
[그림 8] 언어 간 문법적, 파생적 유사성에 따른 분류
이에 개별 언어를 통합하여 하나의 인공지능 모델로 여러 개 언어를 인식하거나 번역하는 통합 인공지능 모델 개발의 필요성이 커지고 있다. 번역의 경우, 언어를 모두 통합하여 하나의 모델로 번역해도 큰 문제는 없을 것으로 예상되나 음성인식의 경우, 개별 언어를 하나의 모델로 통합했을 때 음성인식률 저하가 없도록 그리고 말하는 언어가 무슨 언어인지 혼돈되지 않도록 신뢰성 있게 보장해야 하는 것이 매우 중요하다. 실제 현장에서는 다양한 소음이 발생하며 소음 레벨도 높아 언어 식별에 문제가 일어날 가능성이 높다. 이에 다국어 음성인식 인공지능 통합 모델의 소음에 대한 강인성을 키우는 연구도 진행 중에 있다. [그림 8]은 9개 언어를 통합한 ETRI 모델의 성능을 Whisper 인식기와 비교한 성능으로 통합 모델의 경쟁력이 있음을 보여주고 있다[그림 8].
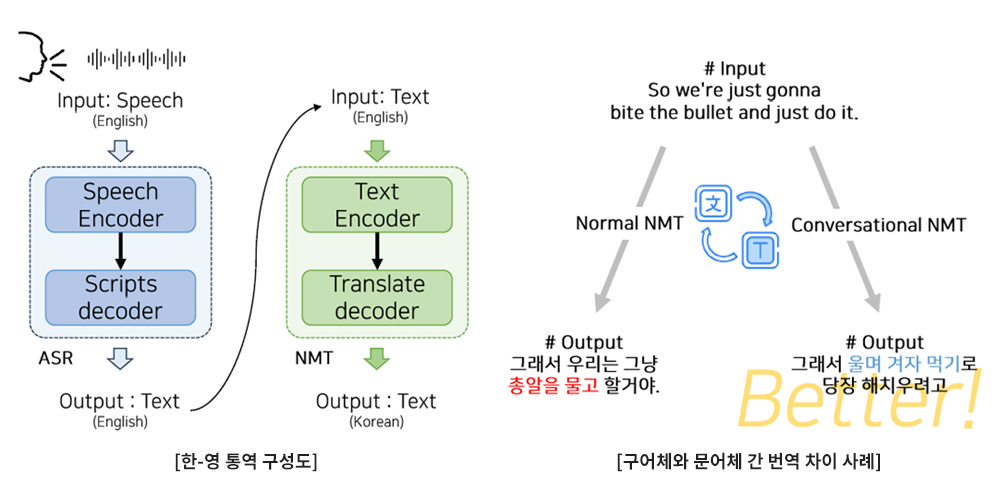
3. 구어체 번역 및 모델 최적화 기술 대화형 자동통역 시 고려해야 하는 문제는 구어체 번역과 언어 간 상이한 특성으로 인한 번역 모델 설정을 언어마다 어떻게 최적화하는가이다. 자동번역의 경우, 외국인과 대화형으로 자연스럽게 언어소통이 가능하도록 구어체 문장에 대한 번역이 가능해야 한다. 구어체 번역은 문어체와 달리 의역이 많기 때문에 직역을 하게 되면 [그림 9]와 같이 의미 전달에 오류가 발생한다[그림 9]. 이에 인공지능 학습 데이터로 두 사람이 서로 주고 받는 대화 문장을 위주로 사용하며 의역이 가능하도록 문맥을 가급적 길게 볼 수 있도록 학습이 필요하다.
<자료> 한국전자통신연구원 자체 작성
[그림 9] Conversational NMT가 필요한 이유
그리고, 아시아권 언어나 유럽어 등 언어 간 특성이 달라 트랜스포머 모델의 파라미터 설정도 다를 것으로 예상된다. 이에 언어별 트랜스포머 번역 모델의 최적화를 수행하였고, 경험적으로 설정되었던 언어별 번역 모델의 파라미터 값들을 실험을 통해 최적하였다. 기존 연구에서 부족했던 아시아 언어권 번역 연구에 주목하여 한국어-영어/일본어/중국어 번역 모델을 개발하고, 각 파라미터가 언어쌍 별로 미치는 영향을 심층 분석하였다. 이를 위해 트랜스포머 기반 번역 시스템을 대상으로 학습 단계와 추론 단계로 나누어 주요 파라미터들이 어떻게 성능에 영향을 미치는지 실험을 수행하였다. 학습 단계에서는 어휘 통합 여부, 어휘 크기, Embedding weight sharing 등의 파라미터를 변화하여 성능에 미치는 영향을 분석하고, 추론 단계에서는 Beam size, Output length ratio 등을 다양하게 변화시켜 가며 한국어를 중심으로 영어, 일본어, 중국어로 구성된 총 200만 문장 데이터 셋을 활용, 다양한 파라미터 값 변화에 따른 성능 변화를 체계적으로 비교ㆍ분석하였다. 본 고를 통해 제시된 최적 파라미터 설정은 향후 한국어를 포함한 다양한 언어 조합을 대상으로 하는 다국어 번역 모델 개발에 있어 중요한 가이드라인으로 활용될 수 있을 것으로 기대된다.
4. 음성인식 결과의 가독성 개선 기술 음성인식 결과로부터 구두점 복원 등 가독성 문제가 번역에 영향을 미친다. 특히, 음성인식 결과에서는 나오지 않는 문장부호는 번역하거나 대화를 이어갈 때 매우 중요한 정보이다. 과거 음성인식기 훈련에 사용되는 음성 데이터베이스의 전사 데이터는 대부분 한글화된 발음표기의 형태로 학습했었으나, 최근에는 아라비아 숫자, 영문표기 등 있는 그대로 철자 표기를 전사문으로 사용한다. 그럼에도 불구하고 음성인식 결과 중 구두점이 제대로 출력이 안되거나, 숫자나 영어가 한글로 나오는 경우가 빈번하게 있다.
<자료> 한국전자통신연구원 자체 작성
[그림 10] 구어체를 문어체로 변환하는 Spoken-to-Written 변환용 인공지능 모델
한글화된 숫자나 영어 출력 결과를 그대로 사용할 경우, 문장의 가독성을 저하시키고 중의적인 의미를 가져 번역 오류를 일으킨다. 따라서 음성인식 추론 시 출력 결과를 철자 표기로 통일시키는 과정이 전체적인 시스템 향상에 매우 중요하다. 이와 동시에 대화체 전사문 속에는 간투사나 더듬거림과 같은 구어체 요소가 포함되어 있으므로 이를 정제된 형태의 전사문으로 수정하는 것이 필요하다. [그림 10]은 트랜스포머 모델을 이용한 Spoken-to-Written(STW) 변환 모델로 [표 1]과 같은 가독성 있는 결과로 변환해준다[그림 10]. 한국어 문장에 포함된 숫자와 영어의 한글화된 발음 표기(spoken form)를 아라비아 숫자나 영어 철자 표기(written form)로 변환하는 동시에 간투사, 더듬거림과 같은 구어체 요소를 정형 문법에 맞게 표현하는 STW 텍스트 변환 기술도 중요하다[6][7].
[표 1] STW 적용 전후 결과와 번역에 미치는 영향 비교
| 구분 | 한국어 표현 | 한-영 번역 결과 |
|---|---|---|
| Spoke-from text | 제가 미국의 아이비엠 연구소에 갔습니다. | I Went to the Ivy M Institute in the United States. |
| K-STW output | 제가 미국의 IBM 연구소에 갔습니다 | I Went to IBM Research in the United States. |
| Spoke-from text | 비엠더블유 코리아는 천구백구십구년부터 해외 본사 인턴 프로그램을 운영하고 있다. | BMDoubleU Korea has been running an internship program for overseas headquarters since one thousand nine hundred and ninety-none |
| K-STW output | BMW 코리아는 1999년부터 해외 본사 인턴 프로그램을 운영하고 있다. | BMW Korea has been running an internship program at its overseas headquarters since 1999. |
| Spoke-from text | 우리는 삼백칠십오억 달러의 기름을 한 방울이라도 다 외국에서 사와야 하지 않으면 안 되는 에너지 빈국의 나라 | We’re and energy-poor country that has to buy every single drop of our $375 billion in oil from foreign countries. |
| K-STW output | 우리는 375억 달러의 기름을 한 방울이라도 다 외국에서 사와야 하지 않으면 안 되는 에너지 빈국의 나라 | We are an energy-poor country that has to buy every drop of our $37.5 billion in oil from foreign countries. |
<자료> 한국전자통신연구원 자체 작성
최근에는 LLM(Large Language Model)을 이용한 가독성 개선 연구도 진행 중인데, 기존에 지도학습(Supervised learning)으로는 학습에 한계가 있고, 학습에 포함되지 않은 패턴인 경우, 제대로 변환이 안되는 문제가 있다. 이에 비지도(unsupervised learning) 방식으로 대용량 데이터로 학습된 사전 학습모델을 기반으로 추가적 지도학습을 하게 된다면 가독성과 패턴 커버리지 측면에서 도움이 된다. 특히, LLM의 경우, 문맥을 길게 보기 때문에 구두점이나 영문, 숫자 등을 문맥에 맞게 복원하거나 추론이 가능해 앞으로 많이 활용 가능한 방법이다[8][9].
5. 고유명사 인식 및 번역 기술 마지막으로 외국인의 한국어 고유명사 발성을 어떻게 인식하느냐이다. 외국인이 한국을 방문하는 경우, 한국어 지명, 지하철 역명 등 고유명사가 포함된 질문을 많이 하게 되는데 이런 경우, 한국어 고유명사에 대한 외국인의 발음이 부정확하고 음운 변이 또한 다양해서 음성인식 오류율이 매우 높다[10]. 게다가 외국어 문장 내 한국어 고유명사가 포함되는 경우가 극히 드물어 문맥 측면에서도 인식을 어렵게 한다. 일반적으로 지명, 사람 이름이나 숫자 및 전문용어 등 이러한 단어들은 통상 모국어 인식이라 하더라도 오류율이 높은데, 외국인이 발성하는 고유명사나 전문용어는 더욱 어려운 수준이다. 외국인을 대상으로 튜닝용 데이터를 수집한다고 해도 외국인이 한국어 고유명사를 잘 발성하기 힘들어하고, 수십 명의 외국인을 대상으로 여러 개 언어에 대한 데이터를 도메인마다 수집하는 것도 사실상 어려워 비용 부담 없이 해결 가능한 방안이 아직 명확하지 않다. 이에 외국인이 발성한 문장 내 포함된 한국어 고유명사를 좀 더 잘 인식할 수 있도록 발음 변이 현상에 대한 음향적인 분석과 한국어 고유명사가 포함된 문맥을 인공지능 모델에 강화하는 연구가 필요하다. 이를 위해 공학, 언어학, 음성학, 외국어 교육학 등 다학제간 연구를 통한 해결이 가장 바람직해 보인다.
Ⅳ. 결론
최근 인공지능의 학습 능력이 비약적으로 발전함에 따라 한동안 정체되어 왔던 자동통역 기술도 여행/일상 통역, 회의 통역, 국제 컨퍼런스 통역, 다문화 가족용 민원 통역, 한류 콘텐츠 자막 통역 등 일상생활 언어장벽 해소에서부터 메타버스 가상환경 비즈니스, 비원어민 원격 교육, 국제 행사용 전시 산업, 다자간 비즈니스 회의, 유엔연합 군사작전 수행 통역 등 전문적이거나 경제적 파급효과가 큰 영역으로 확장되고 있다. 자동통역을 위한 양방향 인터페이스도 스마트폰에서 투명 디스플레이, XR/AR 글라스까지 다양해지고 있으며[11], 통역 가능한 언어도 100여개에 가까운 다국어 서비스까지 지원이 가능해 이제는 전화기처럼 없어서는 안 될 매우 중요한 기능으로 자리를 잡아가고 있다. 최근에는 국내 체류 외국인이 증가하면서 강력 범죄, 보이스피싱 등 범죄가 급증함에 따라 사건 현장이나 검ㆍ경찰청, 법원에서 언어소통이 중요 현안이 되고 있어 희소 언어 통역 부재, 직역식 통역 한계, 통역 앱의 공적 통제 문제 등에 대한 정부의 대책 수립과 지원이 필요한 시점이다.
[1] 김상훈, “Conversational AI 기반 자동통역 기술 동향”, IITP 주간기술동향 1982호, 2021.
[2] 뉴시스, “무선연결 없이 13개 언어 실시간 통ㆍ번역”, 2024. 1.
[3] 조선일보, ”AI가 동시통역...명동역 가면 13개국어 통한다”, 2023. 12.
[4] 한겨레신문, “일상 파고드는 AI 통역”, 2024. 4.
[5] S.H. Kim, “Automatic Speech Translation”, ICCR, Nov. 2022.
[6] H.J. Choi, et al., “Spoken-to-written text conversion for enhancement of Korean–nglish readability and machine translation”, ETRI Journal, 2024.
[7] Devaraju Vinoda, “What is Text Normalization(TN) and Inverse Text Normalization(ITN)?”, Medium, Dec. 2022.
[8] Monica Sunkara, et al., “Neural Inverse Text Normalization”, Amazon AWS AI, Feb. 2021.
[9] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint arXiv:1409.0473, 2014.
[10] Jinxi Guo, Tara N Sainath, and Ron J Weiss, “A spelling correction model for end-to-end speech recognition,” ICASSP, May. 2019.
[11] Philipp A. Rauschnabel, et al., “What is XR? Towards a Framework for Augmented and Virtual Reality”, Computers in Human Behavior, Aug. 2022.
* 본 자료는 공공누리 제2유형 이용조건에 따라 정보통신기획평가원의 자료를 활용하여 제작되었습니다.