
음성 딥페이크 탐지기술 동향
●
●
●
* 본 내용은 홍기훈 교수(☎ 02-828-7156, khong@ssu.ac.kr)에게 문의하시기 바랍니다
** 본 내용은 필자의 주관적인 의견이며 IITP의 공식적인 입장이 아님을 밝힙니다.
최근 한 TV 방송에서 노래를 듣고 가수가 부르는 것인지 AI 모델이 부르는 것인지 맞추는 프로그램이 방영되어 인기를 얻고 있다. 이렇게 가수의 음성을 학습하여 가수와 똑같이 노래 부르는 AI 모델을 만드는 딥러닝 기술이 크게 발전하고 있다. AI 모델이 사람의 음성을 학습하여 동일한 언어 습관으로 말하는 딥러닝 모델은 2017년 구글에 의해 등장하였다[1]. 이 타코트론(Tacotron)이라는 모델은 기존에 음소를 연결하여 음성을 생성하는 레거시 TTS(Text-to-Speech) 시스템에서 들었던 부자연스러운 음성과 달리 매우 매끄럽고 그 사람의 말하는 습관까지 표현하는 획기적인 것이었다. [그림 1]은 TTS와 보이스 컨버전(voice conversion) 처리 과정을 보여 주고 있는데 TTS의 일반적인 메커 니즘은 언어학적인 조합이나 음향 모델링을 통해 사람과 비슷하게 들리는 음성을 생성하는 것으로, 먼저 텍스트 분석 단계에서 입력된 텍스트는 음소, 강세, 억양 등 언어적 특성으로 분석한다. 이후, 이 분석된 텍스트에 언어 규칙을 적용하여 발음과 강세를 포함한 음성 표현으로 변환하고, 음향 모델링을 통해 음성 파형을 생성한다. 생성된 음성 파형은 다양한 합성 기술을 사용하여 실제 음성으로 변환되며, 마지막으로 운율을 추가해 자연 스러운 음성을 만든다[2][3].
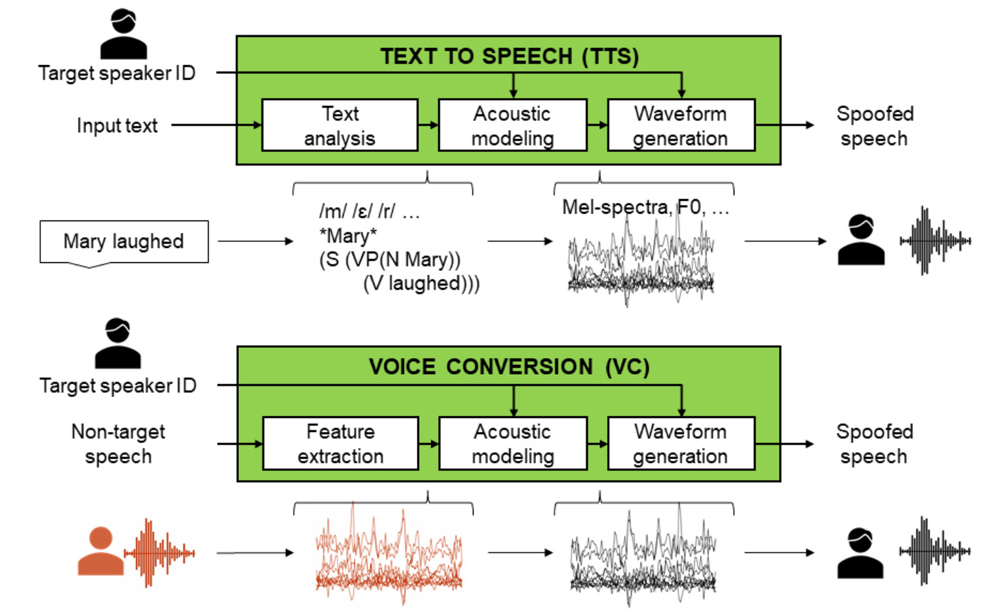
<자료> A. Nautsch et al., “ASVspoof 2019: Spoofing Countermeasures for the Detection of Synthesized, Converted and Replayed Speech”, in IEEE Transactions on Biometrics, Behavior and Identity Science, Vol.3, No.2, April 2021, pp.252-265.
[그림 1] 딥러닝 기반 음성 합성 기술
심층학습과 신경망의 발전은 TTS(텍스트 음성 변환) 기술이 “자연스럽고 표현력 있는” 음성을 생성하게 했고, 이로 인해 기계 음성과 사람의 음성을 구별하기 어려워졌다. 최근 몇 년간 딥러닝 모델인 트랜스포머(transformer) 기반 구조가 TTS의 발전에 중요한 역할을 했다. 특히, 구글의 DeepMind에서 개발한 WaveNet 모델은 고품질 음성 샘플을 생성하며 TTS 시스템 발전에 큰 기여를 했다. 이후 Tacotron 및 Tacotron2 모델은 텍스트에서 직접 스펙트로그램과 파형을 예측하여 합성 과정을 개선했으며, 현재는 GPT와 같은 트랜스포머 기반 모델을 활용한 종단간 음성 합성이 가능해졌다.
보이스 컨버전은 음성의 화자 특성을 변형하면서도 내용의 이해도를 유지하려는 기술로, 주로 화자의 음성 특성을 변경해 다른 사람처럼 들리게 한다. 이 기술은 엔터테인먼트, AI 음성 비서 서비스 등에서 널리 사용되고 있으며, 특히 발화자의 목소리를 대상 화자 처럼 변환하는 데 중점을 둔다. 목표는 언어적 내용이나 의미는 그대로 유지하면서 음성을 변환하는 것이다. 보이스 컨버전은 개인화된 사용자 인터페이스나 영화 더빙, 음성 스푸핑 방지 등 다양한 응용 분야에서 활용된다[2][3].
본 고에서는 AI 변조 음성의 생성과 이로 인한 사회적 문제, 이를 탐지하기 위한 기술 그리고 사회적 대응 정책들을 설명하고자 한다. II장에서는 딥페이크 음성이 악용되는 사례를 소개하고, III장에서는 이러한 딥페이크 음성을 탐지하는 기술을 살펴본다. IV장 에서는 딥페이크 탐지를 어렵게 하는 회피 방법과 대응 연구들을 다루고, V장에서는 사회적 대응을 위한 입법 동향을 파악한 후, VI장에서 본 고의 결론을 제시한다.
II. 딥페이크 음성의 악용
딥페이크는 Deep Learning과 fake의 합성어로 악의적인 목적으로 딥러닝을 통해 생성된 콘텐츠를 의미한다. 이는 딥러닝 생성 모델이 사람이 구분할 수 없는 콘텐츠를 만들고 여기에 인간의 나쁜 의도가 추가되어 악용되는 예이다. [표 1]은 딥페이크 음성이 다양한 목적에 의해 악용되는 실제 사례를 정리한 자료이다. 영상의 경우, 영상에 등장한 인물의 얼굴을 통해 해당 인물로 오인하게 만들고 거짓 정보는 그 인물의 조작된 음성을 통해 전달되어 그 음성의 신뢰성을 높인다.
아무리 좋은 딥러닝 모델들이 등장하여도 이를 악의적 사용자들이 직접 다루는 것은 쉽지 않고 그 영향이 제한적 일 수밖에 없다. 그러나 이러한 기술을 활용하여 사업하는 많은 AI 기업들이 음성 생성 서비스를 경쟁적으로 출시하면서 이제는 누구나 2~3분 정도의 음성 샘플만 확보하면 그 음성과 동일한 연설문 텍스트를 넣어 생성할 수 있게 되었다. 이는 누구나 손쉽게 원하는 목소리로 발화를 만들어 악용할 수 있음을 의미하며 이러한 점을 고려하여 사회적 파급효과를 고민해야 한다.
[표 1] AI 음성의 악용 사례들
| 사례 | 주요 내용 |
|---|---|
| 보이스 피싱 |
- 자녀나 가족의 목소리로 변조된 음성을 통해 도움을 요청하고 이후 보이스피싱범이 협박하여 금전을 요구 - 직장 상사의 목소리로 변조하여 회사 자금의 이체를 요청 |
| 가짜 뉴스 |
- 전쟁 중인 러시아와 우크라이나 대통령으로 변조된 영상에서 음성으로 거짓 소식을 전함 (젤렌스키의 항복 선언/푸틴의 평화 선언) |
| 불법 선거 |
- 튀르키예/슬로바키아 선거 직전, 딥페이크 변조 영상/음성 유포 - 미국 대통령 바이든 목소리로 유권자에게 전화 걸어 선거에 영향을 줌 |
| 투자 사기 |
- 특정 투자방으로 유도하여 유명인(송혜교, 조인성)의 변조 영상/음성을 제공하여 투자자에 대한 신뢰도 상승 |
| 목소리 도용 |
- 스칼렛 요한슨의 목소리를 허가 없이 도용하여 캐릭터나 상용으로 불법 활용 |
<자료> SBS, “빼앗긴 얼굴과 가짜의 덫 - 화면 속 그들은 누구인가?”, SBS 그것이 알고 싶다 1394회, 2024. 4. 20. 보안뉴스, 문가용, “딥페이크 기술 사용한 첫 사기 사건 발생했다”, 2019. 9. 5.
JTBC, “’우크라 대통령, 돈바스 반환 결정?’ 가짜 영상 누가…”, JTBC 뉴스룸, 2022. 3. 17.
Snopes, Dan Evon, “Putin Deepfake Imagines Russian President Announcing Surrender”, Mar. 18, 2022. 한계레, “76개국 슈퍼 선거의 해…‘딥페이크’ 민주주의에 치명상 입힐라”, 2024. 1. 8.
SBS, “‘바이든 가짜 목소리’ 벌금 82억…딥페이크 차단 속도”, SBS 뉴스, 2024. 5. 24. SBS, “‘내 목소리랑 똑같아’...직접 나선 스칼렛 요한슨 ‘분노’”, SBS 8뉴스, 2024. 5. 21.
III. 딥페이크 음성 탐지기술 동향
초기 딥페이크 음성 탐지는 [그림 2]와 같이 화자 인증 시스템(Automatic Speaker Verification: ASV)에서 타깃 화자와 동일한 딥페이크 음성을 구분하지 못하면서 ASV 연구자들이 관심을 가지고 연구를 시작하였다[3]. 2015년부터 ASVspoof 챌린지를 만들어 전송 채널에 따른 음성의 변화나 실제 음성의 짜깁기, 리플레이 음성 탐지가 주요 주제로 개최되다가 2019년부터 딥페이크 음성의 탐지 주제가 강화되었다.
ASVspoof 2021에서는 딥페이크 탐지 트랙이 추가되었고 챌린지에서 주요 연구 주제로 부상하였다. 2023년에 음성 데이터세트의 구성이 지연되면서 개최되지 못하고 명칭을 ASVspoof 5(5번째 챌린지)로 변경하여 2024년에 개최되었고, 탐지 회피나 다양한 노이즈와 음성 생성 방법들이 적용되었다.
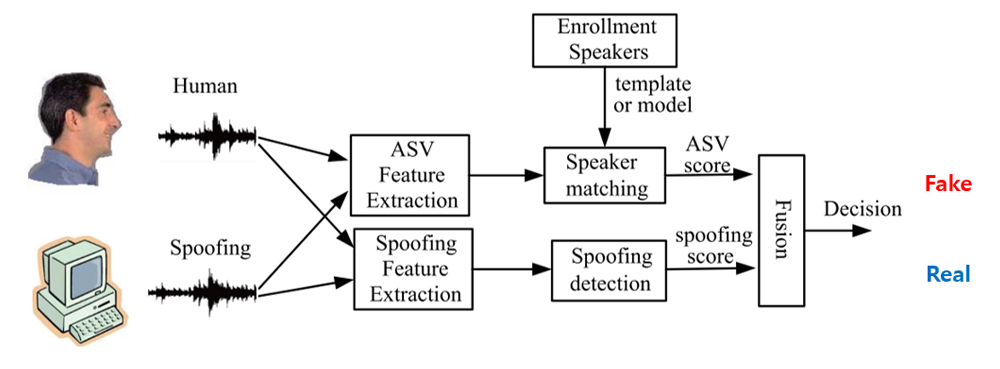
<자료> H. Yu et al., “Spoofing Detection in Automatic Speaker Verification Systems Using DNN Classifiers and Dynamic Acoustic Features”, in IEEE Transactions on Neural Networks and Learning Systems, Vol.29, No.10, Oct. 2018.
[그림 2] 화자 인증시스템의 딥페이크 음성 탐지
딥페이크 음성 탐지의 성능 평가는 주로 EER(Equal Error Rate)이 활용된다. 시스템이 잘못된 대상을 올바르게 인식한 것으로 잘못 판단하는 비율인 False Acceptance Rate(FAR)과 올바른 대상을 거부하는 비율인 False Rejection Rate(FRR)이 같은 지점의 오류율로, 이 값이 낮을수록 시스템의 성능이 우수하다.
1. 딥페이크 탐지 프런트 엔드
화자 인증 시스템은 SV(Speaker Verification) 기능과 딥페이크 대응을 위한 CM (Countermeasure)으로 구분하여 정의하며, 본 고에서는 주로 이 카운터메저에 대해서 설명한다. 딥페이크 음성을 구분하여 탐지하기 위해서는 우선 사람 음성(real)과 딥페이크 음성(fake) 데이터세트를 라벨과 함께 구성하고 이를 음성에 특화된 딥러닝 모델에 학습 시켜야 한다.
초기 모델들에서는 전통적인 신호 처리 기반의 프론트 엔드가 주로 활용되었다. 음성 신호 처리 작업에서 멜-주파수 켑스트럼 계수(MFCC)가 널리 사용되어 왔으며, 이와 유사한 대안으로 선형 주파수 켑스트럼 계수(LFCC)와 역 MFCC(IMFCC)가 있다. 이들은 고유한 주파수 척도를 사용하여 다양한 주파수 대역에 집중한다. [그림 3]은 사람 음성과 딥페이크 음성의 주파수적 차이를 가시화하여 보여 주고 있는데 딥페이크 음성의 고주파 성분이 사람 음성과 다른 것을 볼 수 있다[5]. 그러나 최근 TTS 모델들이 더욱 발전하여 이런 차이만으로는 구분하기 어려워져 다른 음성 특징들이 사용되고 있다.
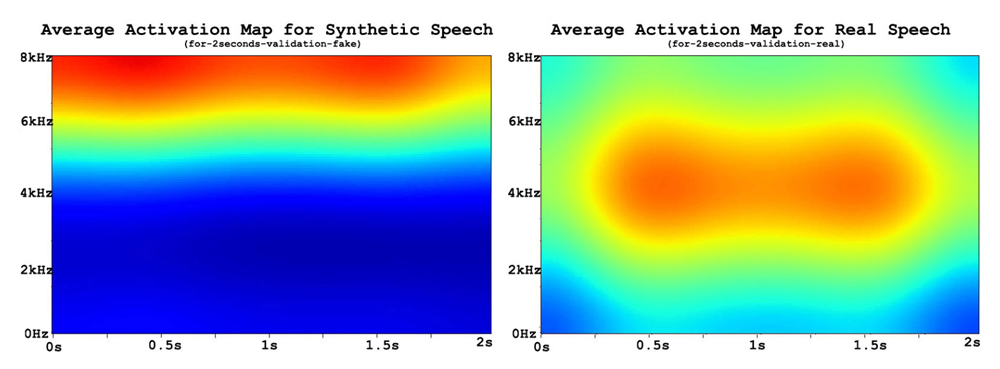
<자료> R. Reimao et al., “Synthetic Speech Detection Using Neural Networks”, 2021 International Conference on Speech Technology and Human-Computer Dialogue(SpeD), 2021.
[그림 3] 주파수 특징으로 구분되는 사람 음성(real)과 딥페이크 음성
최근 음성의 특징 추출을 위한 프론트 엔드에 많이 활용되는 기술은 Wav2vec이며, 이는 음성 인식(Speech Recognition: SR)을 위한 모델로서 음향적 특징과 언어적 특징을 대규모 음성 말뭉치(speech corpus)를 통해 학습하여 좋은 특성을 보인다[6]. 딥페이크 탐지에서는 언어적 특징은 의미가 없으므로 주로 음향적 특징을 사용하여 딥페이크 여부를 판별하고 있다.
2. 딥페이크 탐지 백 엔드백엔드에서는 이렇게 추출된 음성 특징들을 다양한 모델들로 차이를 구분하여 판별한다. [그림 4]는 최신 딥페이크 탐지 모델들이 주로 사용하는 AASIST(Audio Anti- Spoofing using Integrated Spectro-Temporal Graph Attention Networks)를 사용한 모델로 주파수와 시간적 특징을 학습하며, 그래프 어텐션 네트워크(GAT)를 이용하여 각 특징의 연관성과 중요도를 다양한 관점에서 고려해 결합한다[7][8].
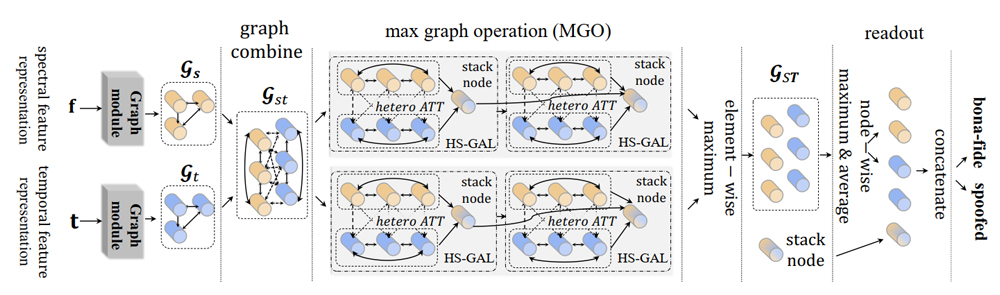
<자료> H. Tak et al., “Automatic Speaker Verification Spoofing and Deepfake Detection Using Wav2vec 2.0 and Data Augmentation”, in The Speaker and Language Recognition Workshop(Odyssey 2022), ISCA, 2022.
[그림 4] AASIST 백엔드를 활용한 딥페이크 음성 탐지모델
Conformer는 “Convolution”과 “Transformer”의 합성어로, 두 가지 기술의 장점을 모두 활용하여 설계된 음성 인식을 위해 개발된 모델이다. 트랜스포머 모듈은 self- Attention 메커니즘을 활용하여 입력 신호의 전역적인 특징을 잘 학습하며, 이를 통해 긴 문맥 내에서 정보의 상관성을 효과적으로 파악할 수 있다. Convolution 모듈은 지역적 특징을 학습하는데 뛰어나고 신호의 짧은 구간 내에서 세부적인 패턴을 학습하기에 적합 하여, 특히 음성과 같은 연속적인 데이터의 지역적 특성을 잘 포착할 수 있다. Conformer는 transformer와 convolution 모듈을 동시에 사용하여 전역적/지역적 특징을 모두 학습 할 수 있으며, 이로 인해 긴 문맥과 세부 패턴의 양쪽 모두에서 정보를 풍부하게 표현할 수 있어 음성 인식 성능이 크게 향상된다[9]. 현재는 앞서 언급한 AASIST와 Conformer 모델이 좋은 성능을 보여 주기 때문에 딥페이크 음성탐지시스템의 백엔드 모델로 주로 활용되고 있다.
Ⅳ. 딥페이크 음성탐지의 어려움
딥페이크 음성 탐지 시스템의 적대적 공격은 [그림 5]의 좌측 그림과 같이 적대적 노이즈를 딥페이크 음성 샘플에 추가하여 가짜 음성이 사람의 음성으로 판별되어 혼란을 주도록 하기 위한 목적으로 주로 사용된다. [그림 5]의 우측 그림은 각 공격 방법별 적대적 노이즈 강도에 따른 판별 오류율의 급격한 증가를 그래프로 보여 주고 있다. 적대적 노이 즈가 증가할수록 공격 성공률은 증가하겠지만 이로 인해 이상 노이즈에 대한 인지는 쉬워져 그 음성 샘플의 신뢰도는 하락할 것이다[10].
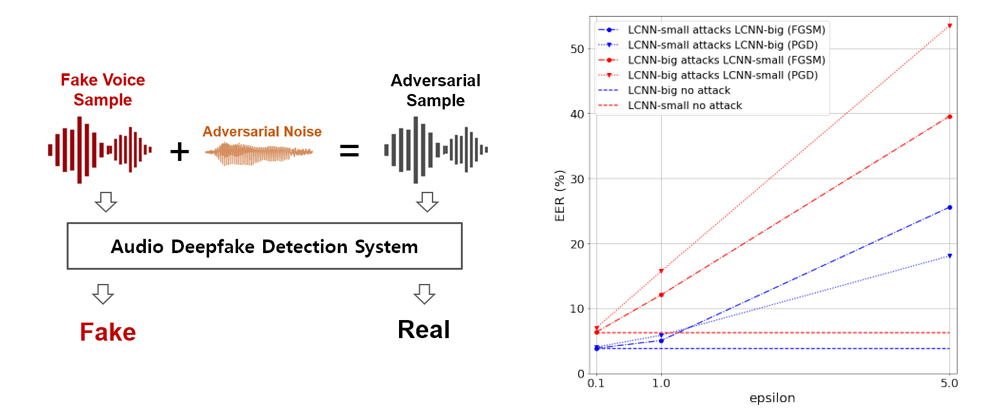
<자료> 숭실대학교 자체 작성
S. Liu et al., “Adversarial Attacks on Spoofing Countermeasures of Automatic Speaker Verification”, 2019 IEEE Automatic Speech Recognition and Understanding Workshop(ASRU), Singapore, 2019.
[그림 5] 딥페이크 음성 탐지의 적대적 공격 예와 노이즈 증가에 따른 탐지 오류율의 상승
적대적 공격에 대한 방어 전략 중 현재 많이 활용되는 방법은 적대적 샘플 훈련으로, 다양한 적대적 샘플을 생성하여 탐지 모델 훈련 시 데이터세트에 포함하여 훈련하는 방법이다[11]. 그러나 적대적 공격 샘플들을 만들기 위해서는 다양한 적대적 공격 방법을 구현하고 매 음성 샘플마다 탐지 모델을 대상으로 실험해야 하므로 대량의 데이터세트 구성은 쉬운 작업이 아니고 자원이 많이 소요된다.
2. 부분 변조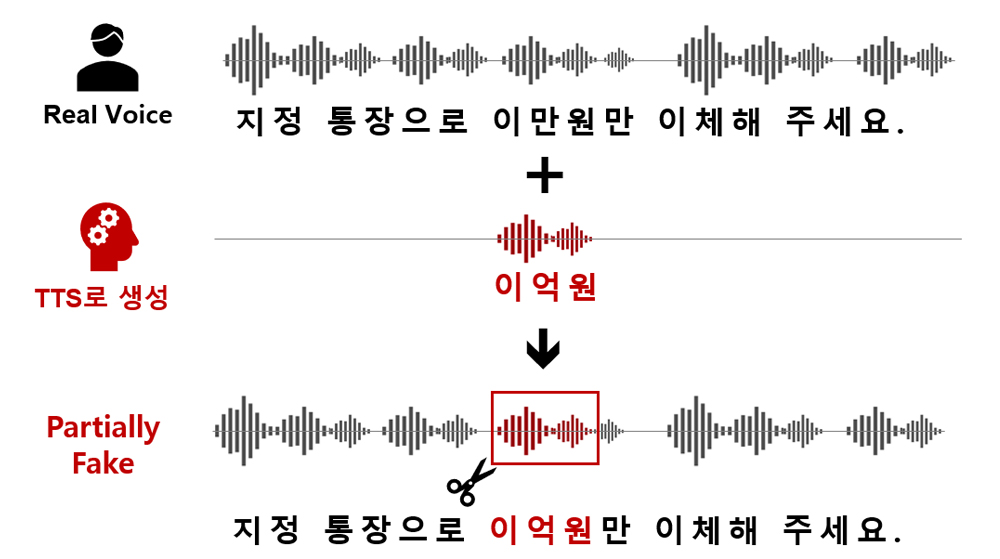
<자료> 숭실대학교 자체 작성
[그림 6] 부분 변조 공격
[그림 6]은 부분 변조(partialfake) 음성의 생성 과정을 보여 주고 있는데 타깃의 실제 음성에서 중요 부분에 TTS로 합성한 음성 일부분을 대체하여 생성한다. 부분 변조 음성은 대부분의 음성이 사람 음성이고 일부분만 딥페이크 음성이므로 사람이 인지하기 어렵고 탐지 시스템도 탐지하기 어렵다. 대부분이 사람 음성이므로 사람 음성으로 판단한다. 반면, 그림과 같은 중요 정보를 변경하면 발화의 내용이 전혀 다른 내용으로 변경되므로 공격의 효과를 극대화할 수 있다. 이러한 부분 변조 음성을 탐지하기 위한 챌린지가 ADD (Audio Deep Synthesis Detection) 2022, PF(Partial Fake) 트랙에서 진행되었다. 부분 변조 음성을 탐지하는 방법은 세그먼트 레벨과 발화 레벨을 나누어 세그먼트의 변조 여부를 확인하는 방법이다. 대상 발화에 다른 발화 세그먼트를 무작위로 삽입하여 변조된 클립의 시간 도메인에서 불연속성을 찾는 방법도 제안되었다. ADD 2022에서 네 번째로 제안된 방법은 부분 조작된 오디오를 활용해 데이터 증강을 수행하는 것으로 진짜 또는 조작된 음성 세그먼트를 원래 발화의 임의 위치에 삽입하여 증강 효과를 내고 모델이 이를 탐지하도록 훈련한다.
V. 딥페이크 대응 정책
앞서 살펴 본 음성 딥페이크뿐만 아니라 영상, 이미지 등 다양한 딥페이크들이 존재하며 다양한 악용 사례들이 발생하면서 딥페이크 전체에 대한 규제 및 정책이 각 국가별로 준비되고 있다. [표 2]는 이러한 각국의 정책 방향을 보여준다[12][13][14].
[표 2] 각국의 딥페이크 대응 정책들
| 국가 | 주요 내용 |
|---|---|
| EU (유럽연합) |
- “디지털서비스 이용자 보호에 관한 기본법”으로 평가되는 「디지털서비스법」 - 초대형 온라인 플랫폼과 초대형 온라인 검색 엔진 사업자에게 효과적인 딥페이크 대응 조치를 요구 |
| 미국 |
- 딥페이크 책임법안(DEEPFAKES Accountability Act) - 딥페이크 신용사기 방지법안(Preventing Deep Fake Scams Act) |
| 한국 |
- 공직선거법 제82조의8 - ‘딥페이크(deepfake) 영상물 등’의 제작, 반포 등 위법적 행위에 대한 처벌을 강화하는 성폭력범죄의 처벌 등에 관한 특례법 일부 개정 |
<자료> 법제처 법제조정법제관실, “딥페이크 관련 해외 입법동향”, 법제처, 2024.
중앙선거관리위원회, “‘딥페이크 영상등’ 이용 선거운동 관련 법규운용기준”, 2023. 12. 28.
김진우, “‘딥페이크(deepfake) 영상물’에 대한 처벌이 강화됩니다”, 검찰국, 보도자료, 2020. 3. 17.
[표 2]에서 유럽연합은 초대형 온라인 플랫폼과 초대형 온라인 검색 엔진은 구조적 위험에 대응하여 비례적이며 효과적인 완화 조치를 마련하도록 하고 있으며, 이러한 조치에는 생성/조작된 비디오, 오디오, 이미지가 실존 인물/사물/장소 등과 매우 유사하여 진짜처럼 보이는 항목에 식별할 수 있는 표시를 통해 구별할 수 있도록 하고 있다. 또한, 서비스 이용자가 쉽게 이러한 정보를 표시할 수 있는 기능을 제공하는 등의 내용이 포함 되어 있다[12].
미국의 “딥페이크 책임법안(DEEPFAKES Accountability Act)”은 딥페이크 기술로 인한 위협으로부터 국가 안보를 안전하게 보호하고 딥페이크로 인해 피해를 입은 피해 자에게 법적인 지원을 제공하기 위한 목적으로 발의되었다. 이 법안에서는 시청각 기록 물이 첨단 기술을 이용하여 만들어졌음을 명확하게 식별할 수 있도록 하는 공개(disclose) 의무, 형사처벌, 민사의 금전적 제재, 피해자 지원, 딥페이크 탐지 등에 관한 내용을 담고 있다. “딥페이크 신용사기 방지법안(Preventing Deep Fake Scams Act)”은 딥페이크를 악용한 시/청각적 조작을 통해 고객의 계좌에 대한 접근 가능성이 높아진 상황을 고려하여 금융 분야에서 딥페이크 대응조직의 구성에 관한 내용을 포함하고 있다. 또한, 「안전하고 보안이 확보되며 신뢰할 수 있는 AI에 관한 행정명령(Executive Order on Safe, Secure and Trustworthy Artificial Intelligence)」은 정책과 원칙, 보안과 AI 안전을 위한 가이드라인, 표준, 모범사례 개발, 백악관 인공지능위원회 설립 등으로 구성되어 있어서 딥페이크 대응을 미리 준비하도록 하고 있다[12].
한국은 공직선거법 제82조의8에서 “딥페이크 영상 등” 제작, 편집, 유포, 상영 또는 게시하는 행위를 하여서는 안 된다고 정의하여 선거에서의 악용을 방지하고 있고[13], ‘딥페이크(deepfake) 영상물 등’의 제작, 반포 등 위법적 행위에 대한 처벌을 강화하는 성폭력범죄의 처벌 등에 관한 특례법 일부 개정을 통해 간접적 규제 방안을 시행하고 있다[14].
VI. 결론
AI 기술의 발전은 기존 IT 기술의 도입 때 보다 우리의 생활 방식을 혁신적으로 변화 시키고 있다. 대부분은 좋은 영향을 주지만 금속으로 만든 칼과 같이 사람이 어떻게 사용 하느냐에 따라 효과는 다르게 나타날 것이다. AI 합성 음성도 많은 곳에 긍정적으로 활용되겠지만 딥페이크와 같이 악용될 경우 큰 피해가 발생할 수 있다. 딥페이크 음성을 악용한 투자 사기와 보이스피싱 같은 사례들이 대표적인 사건들이고 이러한 피해를 막기 위한 노력들로 딥페이크 음성 탐지 기술이 연구되고 있다. 가짜 음성은 잘못된 정보를 직접 전달할 수 있어 딥페이크 음성 탐지의 중요성이 점점 커지고 있다. 이러한 기능을 필요로 하는 국가 기관과 연구 기관들의 관심으로 다양한 연구가 진행되고, 이를 활용하여 딥페이크가 탐지 및 차단되어 안전한 AI 활용 환경이 구축되기를 기대한다. 또한, 본 고를 통해 많은 분들이 딥페이크 음성의 위험을 인지하여 피해자가 되지 않기를 바란다.
[1] Y. Wang et al., “Tacotron: Towards End-to-End Speech Synthesis”, Interspeech 2017, Aug. 2017.
[2] 정수환, “합성 및 변조 음성 탐지 기술 동향”, 융합연구리뷰, Vol.9, 2023. 11. 13.
[3] A. Nautsch et al., “ASVspoof 2019: Spoofing Countermeasures for the Detection of Synthesized, Converted and Replayed Speech”, in IEEE Transactions on Biometrics, Behavior and Identity Science, Vol.3, No.2, Apr. 2021, pp.252-265.
[4] H. Yu et al., “Spoofing Detection in Automatic Speaker Verification Systems Using DNN Classifiers and Dynamic Acoustic Features”, in IEEE Transactions on Neural Networks and Learning Systems, Vol.29, No.10, Oct. 2018, pp.4633-4644.
[5] R. Reimao et al., “Synthetic Speech Detection Using Neural Networks”, 2021 International Conference on Speech Technology and Human-Computer Dialogue(SpeD), Bucharest, Romania, 2021.
[6] Alexei Baevski et al., “wav2vec 2.0: A framework for self-supervised learning of speech representations”, in NeurIPS 2020, Dec. 2020, pp.12449–12460.
[7] J. Jung et al., “Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks”, In IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP 2022), 2022, pp.6367–6371.
[8] H. Tak et al., “Automatic Speaker Verification Spoofing and Deepfake Detection Using Wav2vec 2.0 and Data Augmentation”, in The Speaker and Language Recognition Workshop(Odyssey 2022), ISCA, Jun. 2022, pp.112–119.
[9] E. Rosello et al., “A Conformer-Based Classifier for Variable-Length Utterance Processing”, In Interspeech 2023. ISCA, 2023, pp.5281–5285.
[10] S. Liu et al., “Adversarial Attacks on Spoofing Countermeasures of Automatic Speaker Verification”, 2019 IEEE Automatic Speech Recognition and Understanding Workshop(ASRU), Singapore, 2019, pp.312-319.
[11] L. Nguyen-Vu et al., “On the Defense of Spoofing Countermeasures Against Adversarial Attacks”, in IEEE Access, Vol.11, 2023, pp.94563-94574.
[12] 법제처 법제조정법제관실, “딥페이크 관련 해외 입법동향”, 법제처, 2024. 3.
[13] 중앙선거관리위원회, “‘딥페이크 영상등’ 이용 선거운동 관련 법규운용기준”, 2023. 12. 28.
[14] 김진우, “‘딥페이크(deepfake) 영상물’에 대한 처벌이 강화됩니다”, 검찰국, 보도자료, 2020. 3. 17.
* 본 자료는 공공누리 제2유형 이용조건에 따라 정보통신기획평가원의 자료를 활용하여 제작되었습니다.