


Chapter 2-2
딥러닝 커널 및 활성화 데이터
인코딩/디코딩 소프트웨어
●
●
●
최병호 || 한국전자기술연구원 본부장
| 개발목표시기 | 2021. 12. | 기술성숙도 (TRL) | 개발 전 | 개발 후 |
|---|---|---|---|---|
| 4 | 7 | |||
| 결과물 형태 | SW/HW-IP (Module) | 검증방법 | 자체검증 & 3자검증 | |
| Keywords | 딥러닝, 커널, 활성화, 인코딩, 디코딩, Deeplearning, kernel, activation, encoding, decoding | |||
| 외부기술요소 | 100% 자체 개발기술 | 권리성 | 특허, SW/HW-IP(Module) | |
* 본 내용은 최병호 본부장(☎ 031-739-7470, bhchoi@keti.re.kr)에게 문의하시기 바랍니다.
** 본 내용은 필자의 주관적인 의견이며 IITP의 공식적인 입장이 아님을 밝힙니다.
*** 정보통신기획평가원은 현재 개발 진행 및 완료 예정인 ICT R&D 성과 결과물을 과제 종료 이전에 공개하는 “ICT
R&D 사업화를 위한 기술예고”를 2014년부터 실시하고 있는
바, 본 칼럼에서는 이를 통해 공개한 결과물의 기술이
전, 사업화 등 기술 활용도 제고를 위해 매주 1~2건의 관련 기술을 소개함
II. 기술의 개념 및 내용
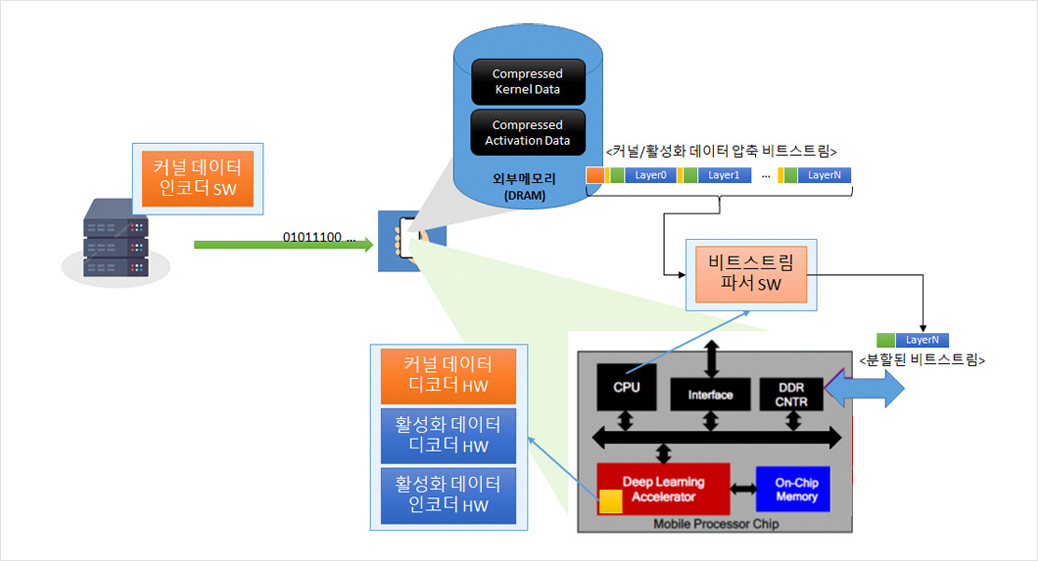
1. 딥러닝 네트워크의 커널/활성화 데이터 압축을 위한 인코딩/디코딩 기술
- 커널 데이터 인코더(SW)/커널 데이터 디코더(HW)
- 활성화 데이터 인코더(HW)/활성화 데이터 디코더(HW)
- 비트스트림 파서(SW)
III. 국내외 기술 동향 및 경쟁력
1. 기술의 특성 및 성능
2. 경쟁기술/대체기술 동향 및 현황
3. 우수성 및 차별성
4. 표준화 및 특허
 표준화 동향
표준화 동향
- 2019년 1월, MPEG 125차 회의에서 NNR(Neural Network Representation)이라고 하는 딥러닝 네트워크 모델 데이터 압축과 관련한
국제 표준화가 시작됨
- 2020년 6월, HHI(독일), Nokia(핀란드), Tencent(중국), Interdigital(미국), 인시그널(한국), 항공대학교/전자부품연구원(한국) 등 20여개 기관에서
활발한 표준화가 진행 중
관련 보유 특허
| 경쟁기술 | 본 기술의 우수성/차별성 |
|---|---|
|
- 커널 데이터 및 활성화 데이터를 압축하기 위한 기술은 크게 양자화
기술과 엔트로피 부호화 기술로 분류할 수 있음 - 양자화 기술은 학습 후 양자화 기술(Post training quantization)과 학습 인지 양자화 기술(Quantization aware training)이 있음 - 엔트로피 부호화 기술로 DeepCABAC이 가장 성능이 우수하나 복잡한 단점이 있음 |
- RLC 및 허프만 코딩에 기반하여 경쟁 기술 대비
저복잡도/고효율을 갖는 엔트로피 부호화기를 개발 - 레이어 별 적응적으로 양자화 기법을 적용함으로써 손실 없이 네트워크 경량화를 달성 |
4. 표준화 및 특허
- 2019년 1월, MPEG 125차 회의에서 NNR(Neural Network Representation)이라고 하는 딥러닝 네트워크 모델 데이터 압축과 관련한
국제 표준화가 시작됨
- 2020년 6월, HHI(독일), Nokia(핀란드), Tencent(중국), Interdigital(미국), 인시그널(한국), 항공대학교/전자부품연구원(한국) 등 20여개 기관에서
활발한 표준화가 진행 중
| No. | 국가 | 출원‧등록번호 | 상태 | 명칭 |
|---|---|---|---|---|
| 1 | 대한민국 | 10-2019-0164757 | 출원 | 계층적 파일 구조를 가진 딥러닝 네트워크 모델 데이터 인코딩/디코딩 장치 및 방법 |
| 2 | 대한민국 | 10-2019-0164756 | 출원 | 심층 신경망 모델의 가중치 부호화 및 복호화 방법 및 장치 |
IV. 국내외 시장 동향 및 전망
1. 국내 시장 동향 및 전망
2. 제품화 및 활용 분야
| 활용 분야(제품 / 서비스) | 제품 및 활용 분야 세부내용 |
|---|---|
| 모바일 엣지 디바이스 | 감시 카메라, 인공지능 스피커, 웨어러블 디바이스 및 소비자 가전 |
V. 기대효과
1. 기술도입으로 인한 경제적 효과
2. 기술사업화로 인한 파급효과
* 본 자료는 공공누리 제2유형 이용조건에 따라 정보통신기획평가원의 자료를 활용하여 제작되었습니다.